Model Context Protocol (MCP) in the Real World

Ask any model to file a GitHub issue. Without repo access, it just talks.
Model Context Protocol (MCP) is a new specification built by Anthropic to extend applications that interact with models by giving them a standardized way to pull in live data and call external tools.
Before MCP, every AI client—chat UI, IDE, or agent shell—needed a bespoke adapter for each data source or service you cared about. These ad hoc solutions became a significant burden to teams, while that time could have been spent developing features.
The MCP server advertises three kinds of building blocks:
- Tools: actions the model can invoke
- Resources: referenceable data blobs or documents
- Prompts: ready-made text snippets the client can drop into context
Servers can run either as a local process on your machine or as a remote microservice behind HTTPS. The wire format is the same, so clients don't care where the code lives.
Anthropic launched MCP in November 2024. Their decision to keep it model-agnostic and permissively licensed opened the door to it becoming a potential industry standard. In March 2025, OpenAI added MCP to its Agents SDK, and in April, Google confirmed support for MCP with the Gemini models.
Anthropic facilitated adoption by releasing reference servers for Google Drive, Slack, Git, Postgres, Puppeteer, and others. Since then, GitHub, Sentry, Zapier, and a growing list of vendors have published their own officially supported servers.
In short, MCP is quickly positioning itself as the industry standard that lets any model reach any service.
Why builders care
- One wire, many plugs. A single JSON-RPC surface replaces the bespoke wrappers you used to keep in sync.
- Ship once, surface everywhere. Expose your Postgres schema or other service once, and it will work with your existing and future clients.
- Ecosystem pull, not push. Over 4,000 open-source servers are already cataloged in Glama, and Anthropic has even teased a first-party MCP registry to streamline the discovery of official servers.
- Platform agnostic. You are free to swap Anthropic for OpenAI (or vice-versa) without touching your servers.
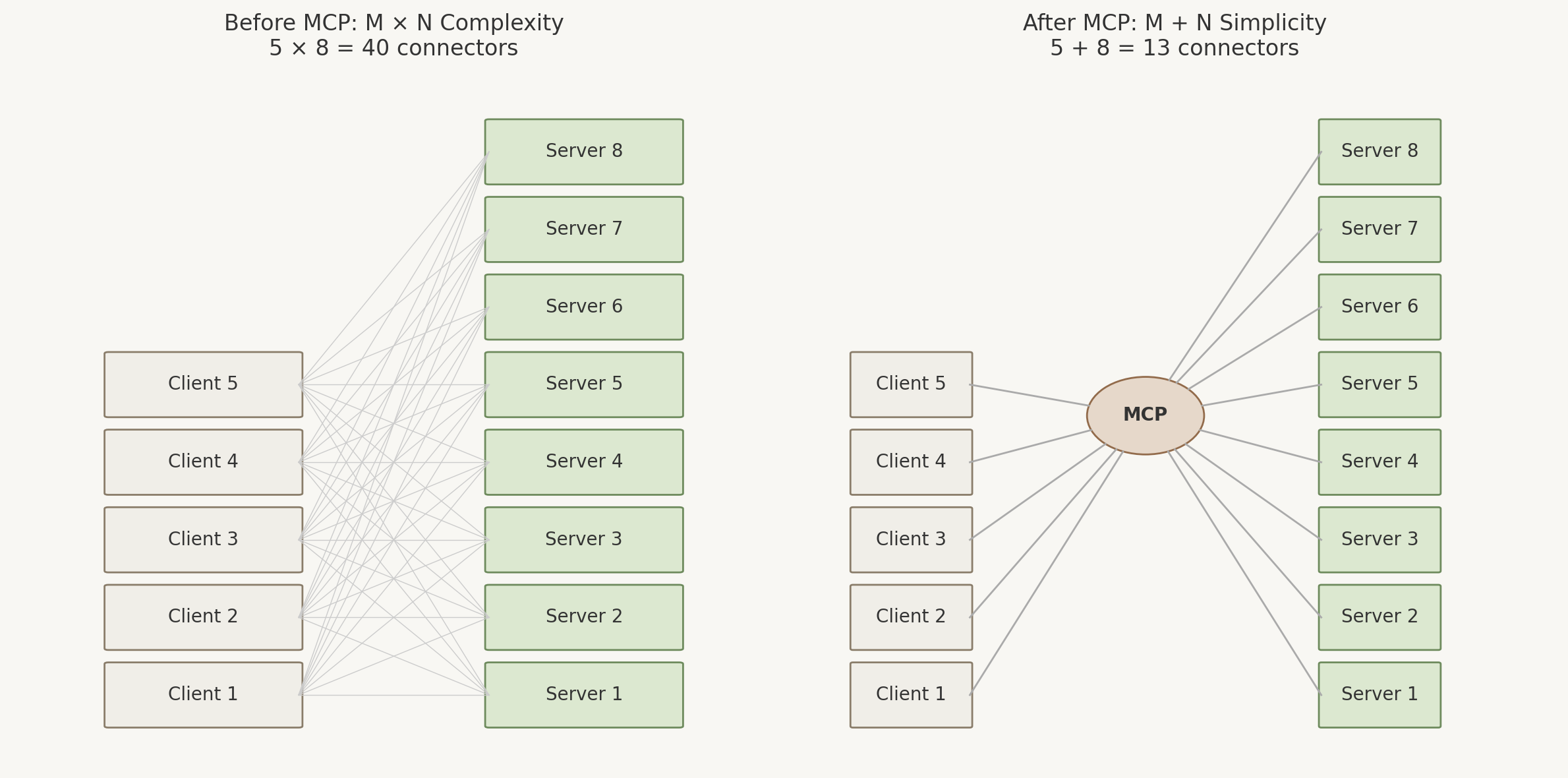
The M × N problem, solved
Before MCP, five clients talking to eight services meant forty separate plugins to build, version, and secure. With the shared JSON-RPC contract, adding a sixth client or a ninth service is one more module, not nine or six. The bottom line is going from M x N to M + N translates to a significant number of engineering hours saved.
It works both ways
If you provide an API, MCP is the clear way to make it LLM-friendly for customers.
If you consume many third-party APIs, ready-made servers are available instead of building from scratch.
In either scenario, you save engineering hours, reduce operating overhead, and cut costs.
Other signals you may want MCP
- Bidirectional agent loops. MCP's RPC is two-way, so a server can ask its client for a completion, enabling nested or recursive chains.
- Publish-once data feeds. Expose your internal incident tracker or analytics store once and every future client can pick it up.
Does MCP replace agent frameworks?
No. Agent frameworks like LangGraph, smolagents, CrewAI, or Semantic Kernel remain the planners. MCP handles the plumbing.
Consider this flow:
Diagnose the spike in 500s and file a ticket.
An agent framework might sketch the plan like this:
- Pull the most recent Sentry events.
- Run a quick SQL against the
errorstable for correlation. - Summarize the root cause in natural language.
- Open a GitHub issue and assign it to someone.
At each step, the agent hands the specific task off to the appropriate MCP server—Sentry, Postgres, GitHub—then moves on. The servers take care of the operational details: authentication, pagination, rate-limiting, and streaming back to the client through MCP's streamable HTTP transport, optionally with SSE when needed, or through stdio when the server is running locally.
The agent never touches those specific concerns. MCP doesn't replace your planner. It simply provides a standard protocol for the agent's plans to be carried out.
Why not just expose my OpenAPI spec?
Sometimes you should. For a small REST service with only a few routes and a single client, handing the raw OpenAPI spec straight to the model may work fine.
But scale flips the math. GitHub's public spec, for instance, exposes ≈ 1,000 operations. Serializing those verb-for-verb means shoving ≈ 70K tokens into every prompt before the user types a word, while also overwhelming the tool selector.
What's a "verb"?
In this case, one distinct HTTP method + path pair—e.g.POST /repos/{owner}/{repo}/issuesorGET /orgs/{org}/invitations.
| Model | Context window | % of window | Cost |
|---|---|---|---|
| GPT-4o | 128K | 55% | $0.35 |
| Claude 3.7 Sonnet | 200K | 35% | $0.21 |
| Gemini 2.5 Pro | 1M | 7% | $0.09 |
That's $90–$350 for every 1,000 requests, and you've already burned up to 55% of the context window that's supposed to hold user text, retrieved docs, and this is just for a single REST API. You likely will require multiple APIs in a real-world scenario, making this approach impractical at scale.
Even worse, accuracy drops, too. LangChain's ReAct-agent study showed that expanding the menu from < 10 tools / 2K instruction tokens to > 100 tools / 77K tokens slashed success rates across every model tested. More tools + longer prompt = more wrong tool calls and missed instructions.
Mapping one operation → one MCP tool, though, is rarely what you want anyway. Typically, only a subset of your API operations should be exposed through your MCP server anyway. The better OpenAPI-to-MCP generators can collapse related routes, tag only selected operations, or bundle endpoints together for more meaningful, high-level actions.
But someone still has to curate the spec. In other words, you'll need to decide which verbs belong together, hide internal routes, and possibly write descriptions. A purpose-built MCP server is the ideal approach.
GitHub's official MCP server, for example, exposes 36 high-level actions. That's already a significant improvement, reducing the token load to now only a few thousand per prompt. But the performance you see will still leave something to be desired, and we can do better.
With dynamic tool discovery, we can group actions into opt-in sets (issues, pull_requests, repos). Only the tools relevant to the current task are loaded, which brings the cost down even further and, most importantly, reduces tool confusion.
Security concerns
Most MCP threats boil down to the same supply-chain and zero-trust problems we already harden against in modern DevOps. SBOMs, signed artifacts, egress allow-lists and IaC reviews still work. You just need to apply them to every MCP server you load.
- Tool poisoning: A server hides malicious instructions inside an "add-label"-style tool, coaxing the LLM to leak files or run shells. Mitigation: Show the entire description in the UI and execute only digest-pinned servers. Any new hash is blocked until diff-review and security checks pass.
- Credential piggybacking: Server A tricks the model into forwarding OAuth tokens meant for Server B. Mitigation: Keep each token in its own auth-frame and have the client refuse any attempt to relay credentials to another server.
- Sleeper / rug-pull: After initial approval, a server updates its manifest to inject "proxy all email," hijacking future sessions. Mitigation: Allow only version-pinned releases and require explicit re-approval whenever the manifest or hash changes.
- Local supply-chain drift: Pulling or retagging a "trusted" repo/image can smuggle in code that reads
~/.ssh. Mitigation: Mirror servers in an internal registry with locked digests and run each host in a least-privilege sandbox. - Auth adoption gaps: OAuth 2.1 is in the spec, yet many community servers still use raw header/query tokens. Mitigation: Admit only servers that use the SDK's OAuth flows (PKCE, device-code, etc.) and refuse startup when hard-coded long-lived tokens are detected.
- Transport migration: SSE holds a long-lived stream per connection and can exhaust file descriptors; Streamable HTTP is now the default, but some clients lag. Mitigation: Use Streamable HTTP whenever both ends support it and keep SSE only for genuine server-push cases until all clients migrate.
- Runtime sandbox: Even a signed MCP host opens a live bidirectional RPC channel. Mitigation: Run hosts inside sandboxes and block outbound traffic by default, allowing only the specific domains and ports each server needs.
Bottom line: Treat every third-party MCP server as third-party code. Pin it, sandbox it, and make its permissions no broader than a single well-defined task. With these mitigations in place, you will limit the new attack surface.
Before you roll out
- Inventory servers and rank data sensitivity.
- Scope egress and FS access per server.
- Fork OSS servers into your own org, pin digests.
- Fail builds on manifest hash changes.
- Load-test sockets/FDs or mandate stateless transport.
Design tips for a pilot
- Keep servers tiny. Think 5–10 tools each. Let the client compose.
- Write human-grade descriptions. The model reads them literally.
- Cache heavy resources instead of refetching every turn.
- Publish evals early. Tool confusion rates tell you when you've exposed too much!
Resources
Official Documentation
- ModelContextProtocol.io: The official source for MCP documentation, specification, and getting started guide.
SDKs and MCP Reference Servers
- Model Context Protocol GitHub: Official MCP repositories, including SDKs for Python, TypeScript, Java, and more.
- MCP Reference Servers: Anthropic-maintained reference implementations demonstrating MCP integration with popular services (Google Drive, Slack GitHub, PostgreSQL, Puppeteer). Essential for hands-on learning.
MCP Directories
- Glama: Indexes, scans, and ranks servers based on security, compatibility, and ease of use.
- Awesome MCP Servers: A curated list of awesome Model Context Protocol (MCP) servers.
Recommended Courses
- MCP: Build Rich-Context AI Apps with Anthropic: MCP course covering MCP server and client development and practical chatbot integration.
- Hugging Face Model Context Protocol (MCP) Course: Free, interactive MCP course blending theory, practice, and community-driven application development.
Developer Tools
- MCP Inspector: Interactive GUI and CLI for testing and debugging MCP servers.
Industry Adoption & Commentary
- Anthropic Blog: Introducing the Model Context Protocol: Original launch post detailing MCP's motivations and roadmap. November 25, 2024.
- Latent Space: Why MCP Won: An analysis of MCP's adoption, technical strengths, and developer community engagement. March 10, 2025.
- Latent Space: The Creators of MCP: The MCP authors share the story behind its creation, the challenges they overcame, and what's next for the protocol. April 3, 2025.
- The Verge: Interview with Microsoft CTO Kevin Scott: Microsoft CTO Kevin Scott explores how AI agents and open standards like MCP could decentralize web search. May 19, 2025.
Member discussion